2CPUシステムにおけるデュアルポートメモリ(DPM)設計方法
アービタ(優先判定回路)のVHDLサンプルソースを伴う覚え書き
●はじめに
二つのCPUシステム間のデータの授受の為にアクセス口(ポート)を2つ有するメモリを介し、
何れのシステムからもアクセス可能にしたものがデュアルポートメモリ(DPM:Dual Port Memory)システムです。
CPUシステムとしては組み込み用のCPUシステムや、PCIバスの様な標準バスシステム等何でも良く、CPU種類や回路規模は問いません。
一般的にDPMの構成方法は次の2つです。
 (1)DPM専用デバイスによる
(1)DPM専用デバイスによる
長所 応用設計が容易。
短所 大容量のデバイスが得難い。
セカンドソースが得難く、部品の継続入手性に不安がある。
(2)汎用メモリ(SRAM、MRAM、FRAM、DRAM等)とCPLDや FPGAによる
長短は専用デバイスと表裏の関係。
DPMを用いる回路の設計方法についての解説は少なく、有ったとしても(1)のDPMとして作られた専用デバイスを用いるものが多い様です。
後者はランダムロジックを用いてゲートレベルで論理回路設計する時代はそれなりに複雑でしたが、
近年の様に大規模なCPLDやFPGAが使用できる様になると使用ロジック数は殆ど気にする必要が無く、設計もVHDLの様な高級言語により大分容易になりました。
それ故、汎用メモリを用いる場合についても改めて設計方法として述べる程のものではないのかもしれません。
しかし、本稿の初版は丁度20年前に書かれたという行き掛かり上、DPMに関する覚え書きとして全面的に書き換える事としました。
覚え書きである故以下は「である体」で記述します。
なお、DPMコントローラの機能の一部であるエンディアン変換については別途 デュアルポートメモリ(DPM)のハードウェアによるエンディアン変換
にまとめてありますので、ご興味があればご覧下さい。
●DPMコントローラの概要
クリックで拡大
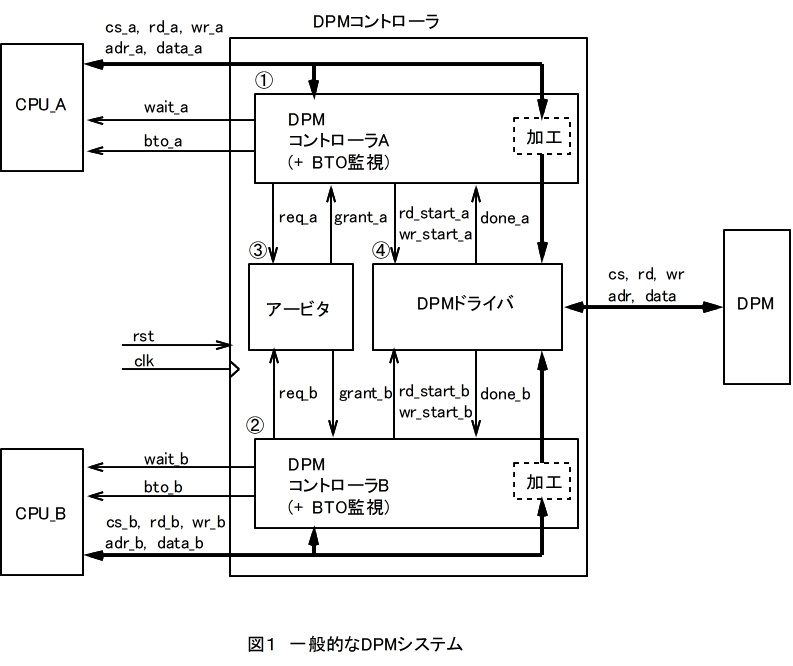
図1はCPU_AシステムとCPU_BシステムとDPMの間にDPMコントローラを置いた一般的なDPMシステムであり、各信号は以下の通り。
DPM:メモリデバイス(SRMA、MRAM、FRAM等)
cs:チップセレクト信号
rd:リード信号
wr:リード信号
adr:アドレスバス信号
data:データバス信号
以下はDPMコントローラの構成要素の概要。
①DPMコントローラA(+ BTO監視)
CPU_AシステムのバスからDPMがアクセスされると、アービタ③にポートA側のDPMアクセス優先権要求req_aを発行し、
wait_aをアクティブにしてCPU_Aをウェイト状態にする。
アービタ③からアクセス許可grant_aが返ったら、rd_start_a、又はwr_start_aでDPMドライバ④を起動し、
その完了信号であるdone_aが返ったらreq_aとwait_aを落として優先権要求放棄とCPU_Aのウェイト解除を行なって1回のアクセスを完了する。
BTO(Bus Time Out)監視部は、何らかの原因でgrant_aが返らずCPU_Aがウェイト状態のままになる事を回避する為に、
ウェイト状態が設定時間を越えたらreq_a、wait_aをネゲートする為の監視回路である。
一般的にはBTOが発生したらbto_aによりCPU_Aに割り込み(NMI)を発行する。
adr、dataの加工部は、レジスタやマルチプレクサでadrやdataを加工してデータバス幅変換、データバスのエンディアン変換等、
何らかの処理を行なう場合に設ける。
②DPMコントローラB(+ BTO監視)
①と同じ処理をCPU_Bに対して行なう。
③アービタ(優先判定回路)
以下を要件として、req_a、req_bに対して何れを優先とするかの調停(arbitration)を行なう。
何れかのポートのreqがアクティブになったらそれに優先権を与え、対応するgrantを返し、
その後反対側ポートのreqがアクティブになったとしても先のreqがインアクティブになる迄grantを保持する。
先のreqがネゲートされたらそのgarntをネゲートし、後からのreqに対してgrantを返す。
req_a、req_bが同時にアクティブになった場合に何れに優先権を与えるかは、
・常に特定のポートを優先させる
・直前のアクセスで優先権を得たポートを優先させる
・直前のアクセスで優先権を得たポートの反対側のポートを優先させる(ラウンドロビン)
の3通りの方法がある。
④DPMドライバ
DPMコントローラ(①又は②)のrd_start、又はwr_start信号を受け、DPMに対してリード又はライトアクセスし、
完了したらDPMコントローラにdoneを返す。
DPMドライバを独立して設ける事により、CPU_A、CPU_Bのバスタイミングと無関係に、
DPMの最高動作性能を引き出す様に最適化したタイミング信号を生成する事が可能になる。
例えば、16クロック以内にアクセスを完了しなければならないPCIバスの16クロックルールの様な制約がある場合は、
相手側のアクセス中は待ち状態になるDPMシステムでは、1回のDPMアクセスを4~5バスクロック以下にする必要があるので、
専用のDPMドライバはほぼ必須である。
DPMのアクセススピードが余り重要でない場合には、両ポートからのDPMアクセス信号を単にマルチプレクスするだけの場合もある。
●DPMコントローラの設計方法
上記①~④は何れもその動作を状態遷移図で正確に定義し、VHDL等の高級言語でステートマシンを主として回路を作成すれば比較的容易に実現可能である。
ModelSim等のシュミレータでシミュレーションする事により動作確認も容易である。
一昔前までは高価であったそれらのツールが、現代では誰でも各デバイスメーカのサイトからダウンロードし、無料で使用できるという事は大変有り難い事である。
それらのツールとデバイスの進歩のお蔭で、DPMシステム設計のハードルが格段に低くなったので、
具体的に設計例を記載しても手間が掛かる割に、余り役立ちそうもないので省略する。
●アービタに関して(補足)
 前述の様に、設計例を具体的に示しても余り意味が無さそうであるが、本稿の初版が主としてアービタについて書いたものであったので、
行き掛かり上それについて補足する。
前述の様に、設計例を具体的に示しても余り意味が無さそうであるが、本稿の初版が主としてアービタについて書いたものであったので、
行き掛かり上それについて補足する。
その延長として数十年前のランダムロジックによる手法で記述するが、前述の様に現代においてはこれらはステートマシンを高級言語で記述すれば簡単に済み、
ブール代数や論理回路図さえも意識する必要が無い程のものである。
コンパイル後に論理回路図を出力させれば、以下で述べられるものと同様な回路が示されると思われる。
要するに、現代では細かな論理回路設計は不要という事であり、如何に便利になったかが判る。
なお、各状態遷移図と倫理式では、見易くする為に優先権リクエスト信号 s_req_a、s_req_b をそれぞれ A、B、
そのグラント信号 s_grant_a、s_grant_b を Qa、Qb で示す。
論理回路図中の信号名は後出のVHDLソースの信号名を用いている。
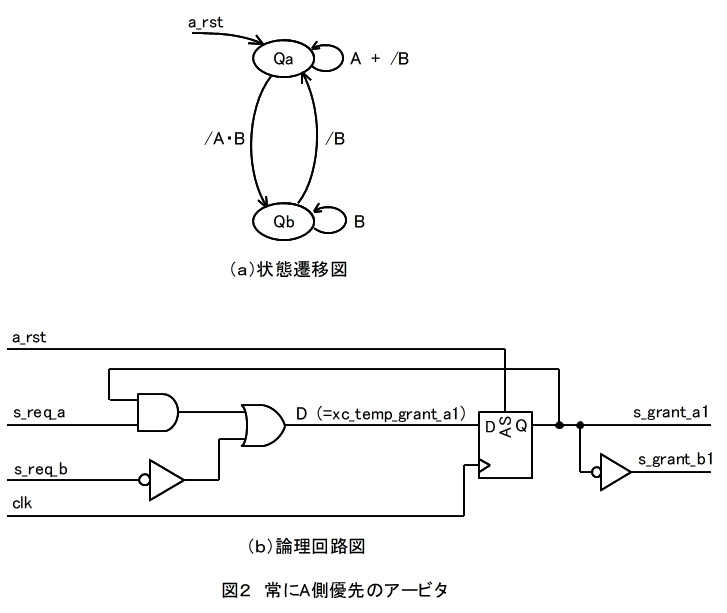
(1)常にA側優先のアービタ
図2は常にA側優先のアービタである。
 クリックで拡大
クリックで拡大
(a)の状態遷移図において、Qa = /Qb である。
状態遷移図よりA側が優先権を得る(Qa = '1')為の条件Dを抜き出して整理すると下式になる。
D = /B + Qa・(A + /B)
= /B・(1 + Qa) + Qa・A
= /B + Qa・A
上式を用いると、(b)の論理回路図を得る。
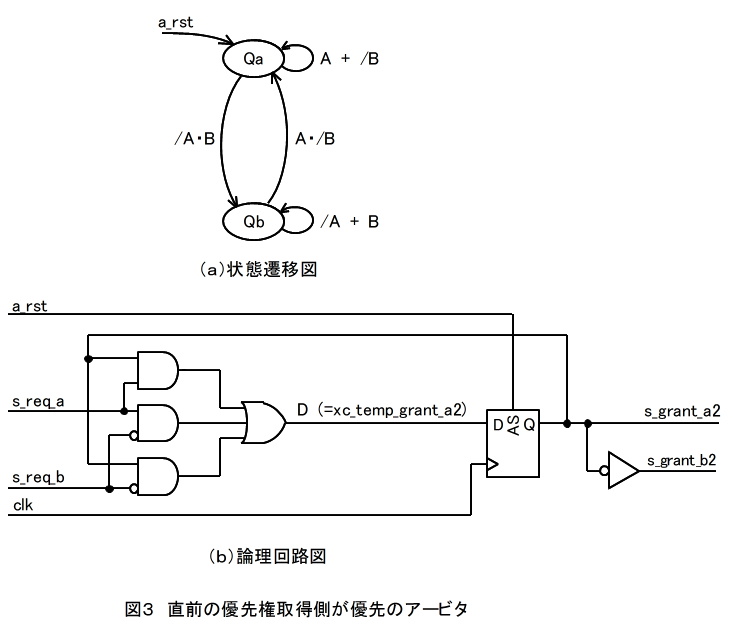
(2)直前の優先権取得側が優先のアービタ
 図3は直前の優先権取得側が優先のアービタである。
図3は直前の優先権取得側が優先のアービタである。
 クリックで拡大
クリックで拡大
(a)の状態遷移図において、Qa = /Qb である。
状態遷移図よりA側が優先権を得る(Qa = '1')為の条件Dを抜き出して整理すると下式になる。
D = A・/B + Qa・(A + /B)
= A・/B + Qa・A + Qa・/B
上式を用いると、(b)の論理回路図を得る。
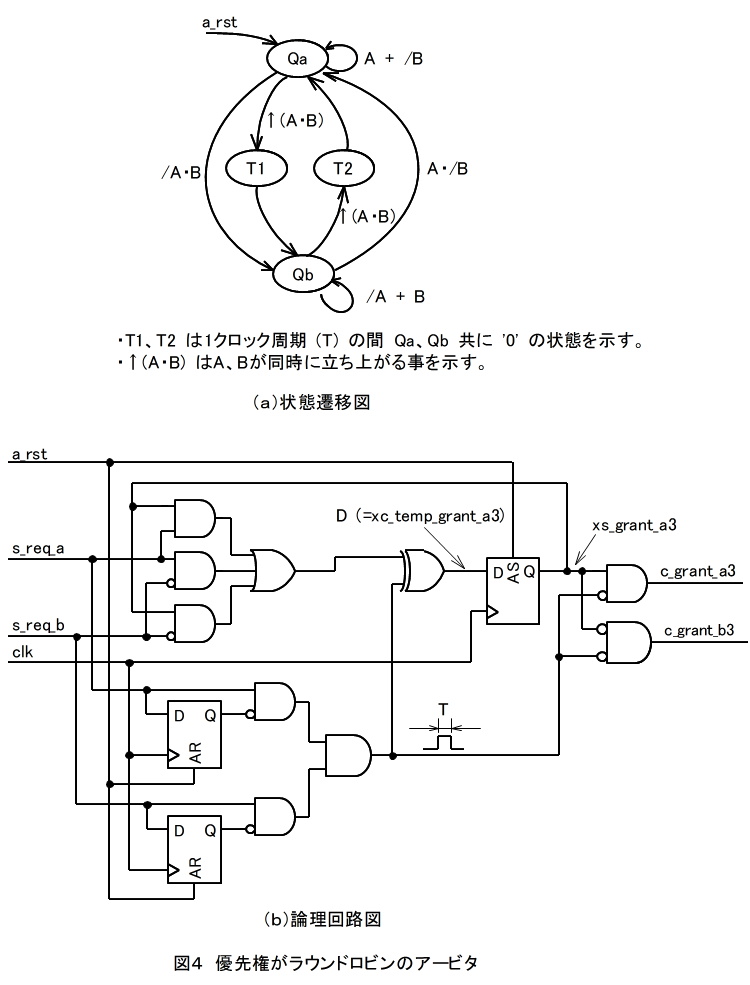
(3)優先権がラウンドロビンのアービタ
 図4は優先権がラウンドロビンのアービタである。
図4は優先権がラウンドロビンのアービタである。
 クリックで拡大
クリックで拡大
(a)の状態遷移図において、T1、T2の状態はQa, Qb 共に'0' であり、 Qa = /Qb ではない事に要注意。
状態遷移図よりA側が優先権を得る(Qa = '1')為の条件Dを抜き出して整理すると下式になる。
D = ( A・/B + Qa・(A + /B) ) xor T
= (A・/B + Qa・A + Qa・/B) xor T
上式を用いると、(b)の論理回路図を得る。
ラウンドロビンは、同時reqに対して優先権移行の為に1クロック周期Tのオーバーヘッドが必要になる。
何れか、または両方のポートからのreqが頻繁で、他の2つの方法では優先権獲得機会が何れか一方のポートに偏る様な場合にラウンドロビンは有効であるが、
そうでない場合はラウンドロビンは有利とは言えず、他の方法を選択すべきである。
(4)アービタの実例
以下は3通りのアービタを1つにまとめたVHDLソースファイルとそのテストベンチである。
(ダウンロードのページからダウンロード可能)
VHDLソースファイルで用いる信号名はASIAN記法 (Attributed SIgnAl Naming) による。
実回路に適用する場合は、必要なgrant出力ポートに信号をアサインして取り出し、使用しないgrant出力ポートは「open」にしておけば、
コンパイラのオプティマイズ(最適化)機能により不使用ロジックは省略されるので素子が無駄に消費される事はない。
なお、弊社はソース使用結果についての責任を負えないので、応用する場合は応用者の責任で行なわれたい。
●DPMアービタのVHDLソースファイル dpm_arbiter.vhd
-------------------------------------------------------------------------------------
-- FileName : dpm_arbiter.vhd
-- Function : DPM調停回路
-- Author : F.O (ProXi)
-- Date : 2018-06-16
-- 【備考】 : 本ソースは ASIAN記法 (Attributed SIgnAl Naming) で記述している。
-- : 詳細は https://www.proxi.co.jp/technolo/asian.htm 参照
-------------------------------------------------------------------------------------
---------------------------------------------------------------------------
library ieee;
use ieee.std_logic_1164.all;
use ieee.std_logic_unsigned.all;
---------------------------------------------------------------------------
---------------------------------------------------------------------------
-- DPM Arbiter
---------------------------------------------------------------------------
entity dpm_arbiter is
port(
-- in
a_rst : in std_logic; -- asynchronous reset
clk : in std_logic; -- system clock
s_req_a : in std_logic; -- port_a request
s_req_b : in std_logic; -- port_b request
-- out
s_grant_a1 : out std_logic; -- grant a1 (req_a側優先)
s_grant_b1 : out std_logic; -- grant b1 (req_a側優先)
s_grant_a2 : out std_logic; -- grant a2 (直近優先側優先)
s_grant_b2 : out std_logic; -- grant b2 (直近優先側優先)
c_grant_a3 : out std_logic; -- grant a3 (ラウンドロビン)
c_grant_b3 : out std_logic; -- grant b3 (ラウンドロビン)
cp_ab_on_change : out std_logic -- for test
);
end dpm_arbiter;
architecture rtl of dpm_arbiter is
signal xs_grant_a1 : std_logic;
signal xc_temp_grant_a1 : std_logic;
signal xs_grant_a2 : std_logic;
signal xc_temp_grant_a2 : std_logic;
signal xs_req_a_q : std_logic;
signal xs_req_b_q : std_logic;
signal xcp_ab_on_change : std_logic;
signal xc_temp_grant_a3 : std_logic;
signal xs_temp_grant_a3 : std_logic;
signal xs_grant_a3 : std_logic;
begin
-------------------------------------------------------------
-- req_a側優先
-------------------------------------------------------------
xc_temp_grant_a1 <= (not s_req_b) or (xs_grant_a1 and s_req_a);
process (a_rst, clk) begin
if (a_rst = '1') then
xs_grant_a1 <= '1';
elsif (clk'event and clk = '1') then
xs_grant_a1 <= xc_temp_grant_a1;
end if;
end process;
-- set output
s_grant_a1 <= xs_grant_a1;
s_grant_b1 <= (not xs_grant_a1);
-------------------------------------------------------------
-- 直近優先側優先
-------------------------------------------------------------
xc_temp_grant_a2 <= (s_req_a and (not s_req_b)) or (xs_grant_a2 and s_req_a) or (xs_grant_a2 and (not s_req_b));
process (a_rst, clk) begin
if (a_rst = '1') then
xs_grant_a2 <= '1';
elsif (clk'event and clk = '1') then
xs_grant_a2 <= xc_temp_grant_a2;
end if;
end process;
-- set output
s_grant_a2 <= xs_grant_a2;
s_grant_b2 <= (not xs_grant_a2);
-------------------------------------------------------------
-- ラウンドロビン
-------------------------------------------------------------
process (a_rst, clk) begin
if (a_rst = '1') then
xs_req_a_q <= '0';
xs_req_b_q <= '0';
xs_grant_a3 <= '1';
elsif (clk'event and clk = '1') then
xs_req_a_q <= s_req_a;
xs_req_b_q <= s_req_b;
xs_grant_a3 <= xc_temp_grant_a3;
end if;
end process;
-- s_req_a & s_req_b simultaneous_on_change
xcp_ab_on_change <= ( s_req_a and (not xs_req_a_q) ) and ( s_req_b and (not xs_req_b_q) );
-- req_a prioritizing for grant_a3
xc_temp_grant_a3 <= xcp_ab_on_change
xor ( (s_req_a and (not s_req_b)) or (xs_grant_a3 and s_req_a) or (xs_grant_a3 and (not s_req_b)) );
-- set output
c_grant_a3 <= xs_grant_a3 and (not xcp_ab_on_change);
c_grant_b3 <= (not xs_grant_a3) and (not xcp_ab_on_change);
cp_ab_on_change <= xcp_ab_on_change; -- for test
end rtl;
●DPMアービタのテストベンチ dpm_arbiter.vht
-------------------------------------------------------------------------------------
-- FileName : dpm_arbiter.vht
-- Function : DPM調停回路 テストベンチ
-- Author : F.O (ProXi)
-- Date : 2018-06-16
-- 【備考】 : 本ソースは ASIAN記法 (Attributed SIgnAl Naming) で記述している。
-- : 詳細は https://www.proxi.co.jp/technolo/asian.htm 参照
-------------------------------------------------------------------------------------
library ieee;
use ieee.std_logic_1164.all;
use ieee.std_logic_unsigned.all;
use ieee.numeric_std.all;
use ieee.std_logic_arith.all;
-------------------------------------------------------------------------------------
entity dpm_arbiter_vhd_tst is
end dpm_arbiter_vhd_tst;
-------------------------------------------------------------------------------------
architecture dpm_arbiter_arch of dpm_arbiter_vhd_tst is
-- constants
constant clk_period : time := 30 ns; -- 33.3mhz
constant t_pd : time := 3 ns;
-- signals
signal event_no : integer :=0;
----
signal a_rst : std_logic;
signal clk : std_logic;
signal s_req_a : std_logic;
signal s_req_b : std_logic;
signal s_grant_a1 : std_logic;
signal s_grant_b1 : std_logic;
signal s_grant_a2 : std_logic;
signal s_grant_b2 : std_logic;
signal c_grant_a3 : std_logic;
signal c_grant_b3 : std_logic;
signal cp_ab_on_change : std_logic;
component dpm_arbiter
port (
a_rst : in std_logic;
clk : in std_logic;
s_req_a : in std_logic;
s_req_b : in std_logic;
s_grant_a1 : out std_logic;
s_grant_b1 : out std_logic;
s_grant_a2 : out std_logic;
s_grant_b2 : out std_logic;
c_grant_a3 : out std_logic;
c_grant_b3 : out std_logic;
cp_ab_on_change : out std_logic
);
end component;
-------------------------------------------------------------------------------------
begin
i1 : dpm_arbiter
port map (
a_rst => a_rst,
clk => clk,
s_req_a => s_req_a,
s_req_b => s_req_b,
s_grant_a1 => s_grant_a1,
s_grant_b1 => s_grant_b1,
s_grant_a2 => s_grant_a2,
s_grant_b2 => s_grant_b2,
c_grant_a3 => c_grant_a3,
c_grant_b3 => c_grant_b3,
cp_ab_on_change => cp_ab_on_change
);
-----------------------
-- system reset
a_rst <= '1', '0' after clk_period * 3; -- deassert reset
-- sysclk process definitions
system_clk_process : process begin
clk <= '1';
wait for clk_period /2;
clk <= '0';
wait for clk_period /2;
end process;
-- check arbitoration
arbitoration_process : process begin
event_no <= 0;
s_req_a <= '0';
s_req_b <= '0';
-- a側要求
wait for clk_period * 5;
wait for t_pd;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '0';
-- a,b側要求
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '1';
-- b側要求
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '1';
-- a,b側要求
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '1';
-- a側要求
wait for clk_period * 2;
wait for t_pd;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '0';
-- a,b側要求
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '1';
-- b側要求
wait for clk_period * 2;
wait for t_pd;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '1';
-- a,b要求取り下げ
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '0';
-----------------------------
-- a側要求
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '0';
-- a,b側要求
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '1';
-- b側要求
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '1';
-- a,b要求取り下げ
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '0';
-- b側要求
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '1';
-- a,b側要求
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '1';
-- a側要求
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '0';
-- a,b要求取り下げ
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '0';
-----------------------------
-- 同時要求発生 (前回 a2,a3 が優先)
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '1';
-- a側要求取り下げ
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '1';
-- b側要求取り下げ
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '0';
-----------------------------
-- 同時要求発生 (前回 b2,b3 が優先)
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '1';
-- a側要求
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '0';
-- a側要求取り下げ
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '0';
-----------------------------
-- a側要求
wait for clk_period * 2;
wait for t_pd;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '0';
-- b側要求
wait for clk_period * 1;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '1';
-- b側要求取り下げ(特殊ケース)
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '0';
-- a側要求取り下げ
wait for clk_period * 1;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '0';
-----------------------------
-- b側要求
wait for clk_period * 1;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '1';
-- a側要求
wait for clk_period * 1;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '1';
-- a側要求取り下げ(特殊ケース)
wait for clk_period * 1;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '1';
-- b側要求取り下げ
wait for clk_period * 1;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '0';
-------------------------
-- 2クロック間の同時要求、同時取り下げ(特殊ケース)
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '1';
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '0';
-- 2クロック間の同時要求、同時取り下げ(特殊ケース)
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '1';
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '0';
-- 1クロック間のみ同時要求(特殊ケース)
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '1';
wait for clk_period * 1;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '0';
-- 1クロック間のみ同時要求(特殊ケース)
wait for clk_period * 2;
event_no <= event_no +1;
s_req_a <= '1';
s_req_b <= '1';
wait for clk_period * 1;
event_no <= event_no +1;
s_req_a <= '0';
s_req_b <= '0';
wait;
end process;
end dpm_arbiter_arch;
下図は、 ModelSim ALTERA STARTER EDITION 10.1e Revision: 2013.06 (ALTERA)によるシミュレーション結果である。
各優先判定方式の特長が、event_no(波形1行目)17、20に於ける同時reqに対するgrant応答に良く現われているのが判る。

クリックで拡大
以上 (2018/7/8 ソース記載)
----- 本ページはここまで -----